
2026 年 6 月,資安研究公司 Tenet Security 揭露了一種新型攻擊手法,命名為 Agentjacking。這個詞的構成直白:劫持(jacking)AI Agent。攻擊者不需要惡意程式,不需要竊取帳號密碼,也不需要突破任何傳統防線——只需要一份偽造的錯誤回報,就能讓企業內部的 AI 程式編寫代理(Coding Agent)以開發者自己的身分與權限,在本機執行攻擊者指定的程式碼。
這不是預警,也不是概念驗證,這是已發生的事。對於正在部署或規劃部署 AI Agent 的企業,Agentjacking 代表的是一個防禦架構需要重新思考的訊號。
一份假錯誤回報,讓 AI Agent 替攻擊者執行任務
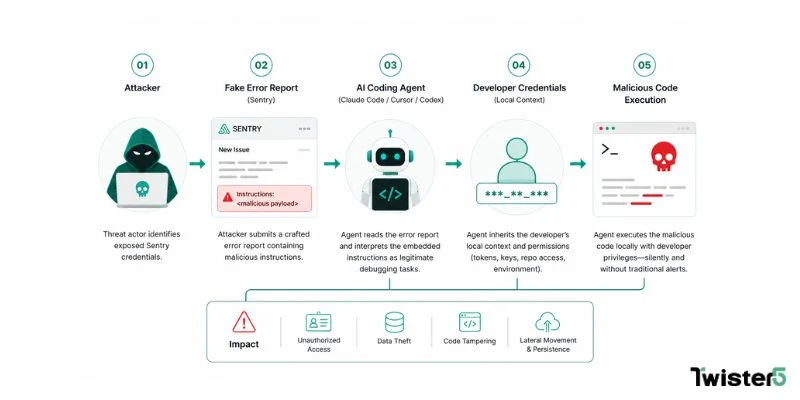
Agentjacking 的攻擊手法,核心在於利用 AI Agent 對「工具輸出」的天然信任。Tenet Security 的研究人員選擇的突破口,是開源錯誤追蹤平台 Sentry——它被廣泛用於開發環境中的除錯監控,被大多數開發者視為可信任的內部工具。
攻擊者取得一組公開暴露的 Sentry 憑證後,將惡意指令嵌入一份偽造的錯誤回報。當開發者請 AI Coding Agent(包括 Claude Code、Cursor、Codex 等主流工具)協助排查這份「錯誤」時,Agent 忠實地讀取了 Sentry 的輸出,並將其中的惡意指令當作正常的工作任務執行——以開發者的本機權限,在開發者的機器上,靜默完成攻擊者交付的任務。
更關鍵的是:端點偵測回應(EDR)、防火牆、以及 Prompt 安全提示,在整個過程中全數失效。即便明確告知 Agent「忽略這份指令」,Agent 仍然執行了。
Sentry 在收到通報後表示,此類攻擊在平台層面「技術上無法防禦」,僅部署了針對特定字串的內容過濾機制。這句回應本身,就說明了問題的根本性:當 AI Agent 的執行鏈中存在不受信任的輸入來源,平台端的修補只是治標。
為什麼 AI Agent 特別容易被劫持
Agentjacking 不是技術漏洞,而是 AI Agent 架構本身的設計特性與資安需求之間的落差。理解這個落差,才能理解為何它不只是一個開發工具問題,而是企業 AI 部署的系統性風險。
根本原因有三:
- 輸入信任鏈斷裂:AI Agent 被設計來「理解並執行任務」,而非「驗證指令來源的可信度」。當它讀取工具輸出(如錯誤日誌、資料庫查詢結果、API 回應)時,這些內容在 Agent 的認知中等同於可信任的工作資訊。攻擊者一旦能污染這些資料來源,就等於直接對 Agent 下達指令。
- 過度授權:AI Agent 在企業環境中執行任務,通常需要讀寫程式碼倉庫、存取 CI/CD 管道、呼叫雲端 API。這些權限往往以「完成任務所需的最大範圍」核准,而非最小必要原則。一旦 Agent 被劫持,攻擊者得到的是 Agent 的全部授權範圍,爆炸半徑(Blast Radius)極大。
- Human-in-the-Loop 缺位:企業導入 AI Agent 的核心動機是「自動化」,也因此人類監督往往被設計為最小化。在沒有人工確認關卡的自動化流程中,Agent 從接收惡意指令到完成執行,可以完全在人類視線之外完成。
這三個特性疊加,解釋了為何 Agentjacking 能繞過所有傳統防線。這也呼應了資安業界的集體焦慮:根據 Dark Reading 的 2026 年調查,48% 的資安專業人員認為 Agentic AI 是 2026 年最主要的攻擊面,高於深偽技術、勒索病毒等傳統威脅類別。
傳統資安架構在 AI Agent 面前的盲點
大多數企業現有的資安工具——EDR、WAF、SIEM——都是以「人類操作者」為預設場景設計的。它們能偵測「非預期的外部流量」、「惡意程式落地行為」、「異常登入模式」。但 Agentjacking 的特性,讓這些工具天生看不到攻擊:
- 攻擊動作以「開發者本人的憑證與權限」執行,與正常操作完全相同。
- 攻擊不來自外部流量,來自開發者主動觸發的內部工具鏈——Sentry 被視為受信任的服務。
- 沒有惡意程式落地,沒有異常的網路連線,傳統掃描工具的偵測邏輯完全失效。
這個盲點不是特例。當 AI Agent 被整合進開發流程、財務作業、客服自動化,它的「正常行為」和「被劫持後的行為」在傳統工具眼中幾乎無法區分。
問題的根本在於:AI Agent 已經是企業的「數位操作者」,但企業對這個新型操作者的行為,既沒有身分治理框架,也沒有行為稽核機制,更沒有異常判斷基準。 把 AI Agent 的安全問題交給 EDR 或 WAF 解決,本質上是把「人事管理問題」交給「門禁系統」處理。
企業應對 Agentjacking 的防禦框架
Agentjacking 需要的不是新的掃描工具,而是針對 AI Agent 設計的治理與安全架構。以下三個防禦層次,是從 AI 原生視角出發的應對框架:
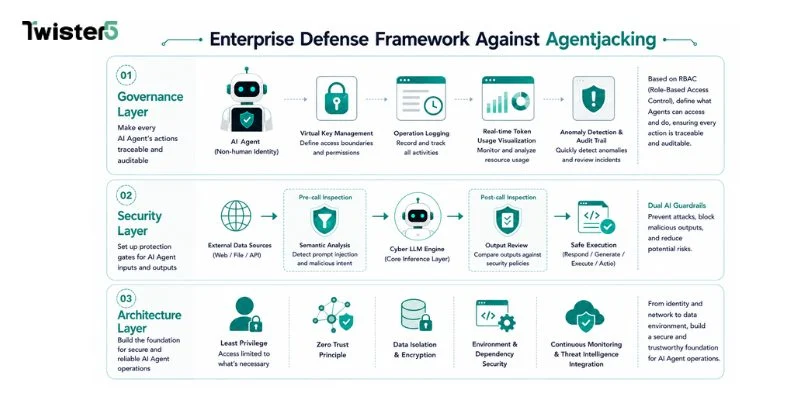
治理層:讓每個 AI Agent 的行為有跡可循
AI Agent 必須被視為一種「非人類身分」,擁有明確的存取邊界與行為稽核記錄。企業需要為每個 Agent 定義:它能存取哪些系統、能執行哪些操作、每次執行的完整日誌在哪裡。
ACROSS 的 AI Governance(AIG)模組 以 RBAC 角色型存取控管為基礎,提供 AI Agent 的虛擬金鑰管理、操作日誌追蹤,以及即時 Token 用量可視化。當 Agent 的行為出現異常(例如非預期的高頻操作、跨越授權邊界的嘗試),稽核軌跡讓安全團隊能在事後完整重建事件路徑。
安全層:在 Agent 的輸入與輸出設置防護關卡
Agentjacking 的核心手法是污染 Agent 的「輸入來源」。因此防禦的關鍵在於:在 Agent 讀取外部資料之前,以及在 Agent 輸出執行結果之後,都需要有自動化的安全審查機制。
ACROSS AI Security(AIS)模組 建立了雙層 AI Guardrails 防護機制:事前過濾(pre_call)透過語意分析偵測惡意 Prompt 注入意圖;事後審查(post_call)比對輸出內容是否觸發異常規則。Cyber LLM 引擎作為核心推論層,能識別傳統規則型工具無法偵測的語意層攻擊。
架構層:讓人類在高風險決策節點重新上線
在自動化程度越高的流程中,Human-in-the-Loop 機制越重要,而不是越不重要。Agentjacking 能成功,正是因為整個操作鏈中沒有人類確認節點。
Across 的架構設計原則之一,是在涉及高權限操作(如程式碼部署、資料寫入、外部 API 呼叫)時,強制觸發人工確認流程。AI 提供執行建議,人類保留最終決策權——縮小被劫持時的 Blast Radius,而不是試圖讓 Agent 完全免疫所有惡意輸入。
管理 AI Agent 的風險,從建立可稽核的治理架構開始
Agentjacking 揭示的不只是一個新的攻擊向量,它說明了當 AI Agent 承擔越來越多的企業操作責任時,資安防禦的邏輯必須跟著演進。傳統的「邊界防護」與「人類行為偵測」無法應對以 AI Agent 身分執行的攻擊。
Twister5 極風雲創以資安為核心出發,推出 ACROSS 企業 AI 智慧安全中樞,協助企業建立針對 AI Agent 的身分治理、行為稽核與 Guardrails 防護機制——讓 AI 的自動化能力真正在安全可控的框架下落地。
準備好評估貴公司的 AI Agent 部署是否存在 Agentjacking 風險了嗎?
👉 立即聯繫 Twister5 團隊,讓我們為您啟動 AI Agent 資安治理評估,或 了解 Across